

Data ingestion using AWS Services, Part 2
Querying AWS S3 data from AWS Athena using SQL.
AWS Athena is an interactive query service that makes it easy to analyze data on Amazon using standard SQL. In this second part of the tutorial, we are going to crawl the migrated data in AWS S3, create table definitions in the Glue Data Catalog using AWS Glue, and query the data using AWS Athena. AWS Glue is a serverless data integration service that makes it easier to discover, prepare, move, and integrate data from multiple sources for analytics, machine learning (ML), and application development.
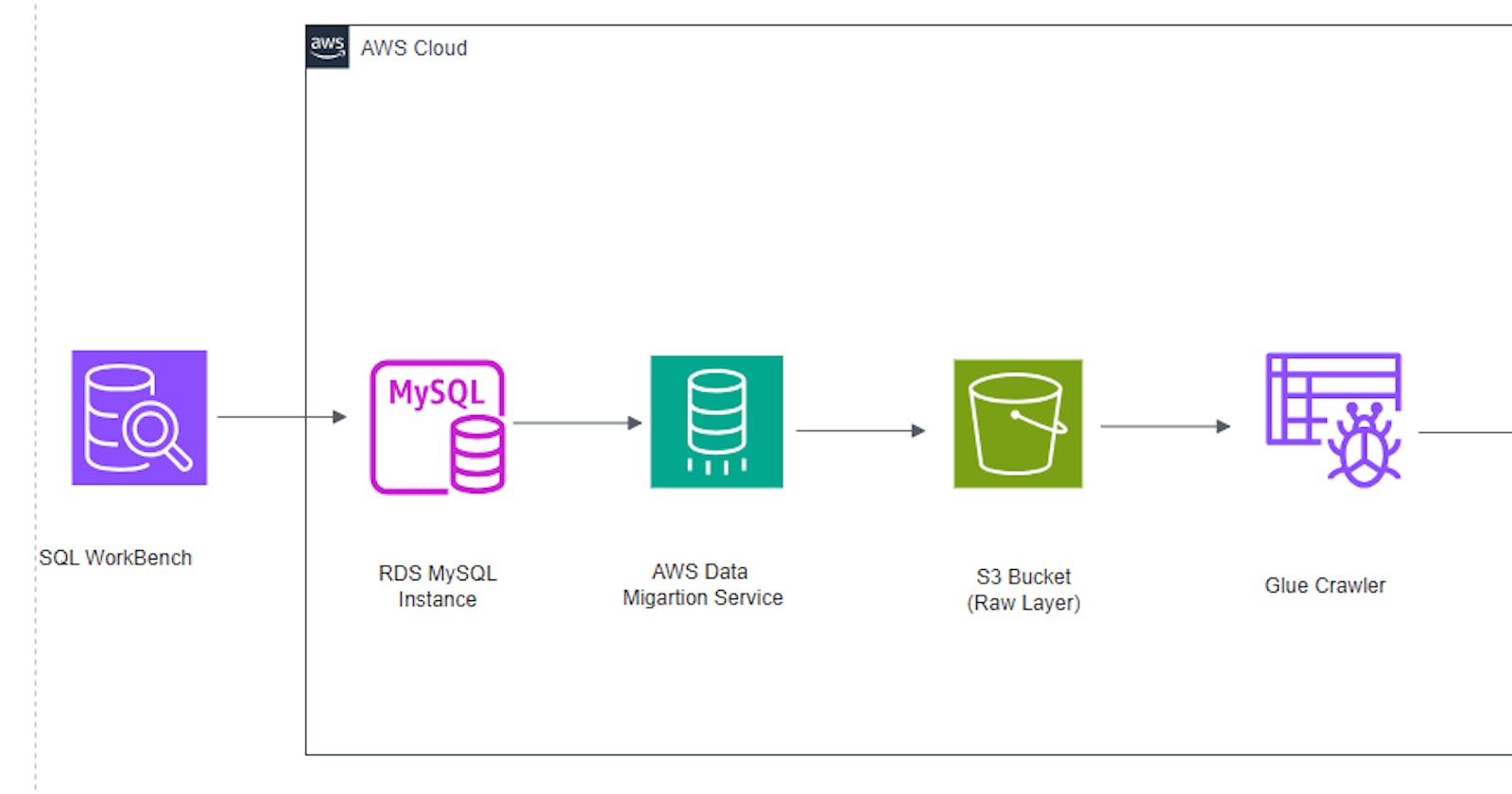
Before you proceed with this hands-on tutorial, make sure you have completed the first part of the tutorial, Data Ingestion using AWS Services Part 1. Below is an architectural diagram of the full project.

1. Search for and select AWS Glue in the top search bar of the AWS console.
2. Click on Crawler and then Create crawler. A crawler accesses your data store (e.g., AWS S3), extracts metadata, and creates table definitions in the AWS Glue Data Catalog.

3. Enter a descriptive name for the crawler job and click Next.

4. Click on Add data score.

5. Under Data source, select S3. Click on Browse S3 to choose the AWS S3 bucket containing the data we want to query. Leave all defaults and click on Add an S3 data source.

6. Verify and click on Next.

7. Create or select an IAM role under Existing IAM role and click Next.

8. Click on Add database under Target database or select a database in the dropdown. Let's create a database called testdb. Click Create database.

9. For frequency, select On demand. This is used to define a time-based schedule for crawlers and jobs in AWS Glue. Click Next.

10. Check all settings and click Create crawler.

11. After the successful creation of the crawler, click on Run crawler to start the crawler job.

12. To check the status of a crawler, click on Crawlers, the name of the crawler, and then Crawler runs.

13. Verify the table and the database by clicking on Tables.

14. Search for and select AWS Athena in the top search bar of the AWS console.
15. Click Query editor. In the query editor, click Settings, then Manage. In the Manage settings, select Browse S3 to select an AWS S3 that will serve as the location of the query result. Click on Save.

16. In the query editor, enter the following SQL statement:'select \ from testbucketformysqldata123_raw limit 10*’. The query selects all the data migrated into the bucket. Note: Substitute the table name with the name of your table.

17. The Query results tab shows the results of the query.

This ends the hands-on project on data ingestion using AWS DMS. Next in the series is SaaS data ingestion using Amazon AppFlow.