

Data ingestion using AWS Services, Part 1
Data ingestion is the process of collecting, importing, and transferring raw data from various sources to a storage or processing system where it can be further analyzed, transformed, and used for various purposes. The goal is to bring in data from various sources and make it available for analysis and decision-making. Data ingestion is usually a crucial first step in a data pipeline.
Data ingestion can be either in batches where data is brought over in bulk at regular intervals, called BATCH DATA INJECTION, or in near real-time, called STREAM DATA INGESTION where data is brought over as soon as it is generated.
The first part of my data ingestion tutorial covers batch data ingestion using AWS services, which I will cover in separate articles. Specifically, I will cover hands-on tutorials on the following topics:
1. Data ingestion using AWS Data Migration Service (DMS)
2. SaaS data ingestion using Amazon AppFlow
3. Data ingestion using AWS Glue
4. Transferring data into AWS S3 using AWS DataSync
Before we delve into the hands-on, let’s create a data lake in AWS Simple Storage Service (S3). All the ingested data in this hands-on tutorial will first be brought over into a bucket in AWS S3, which is a preferred choice for building data lakes in AWS. Amazon S3 is a scalable object storage service offered by AWS. It is designed to store and retrieve any amount of data from anywhere on the web. Data in S3 is organized into containers called bucket. A bucket is similar to a directory or folder and must have a globally unique name across all of AWS. Let’s create a bucket in AWS S3, which will serve as a destination for all ingested data.
To create a bucket, we can use the AWS CLI available through the AWS management console called the CloudShell.
1. Log into the AWS console using an administrative user.
2. Search for and select S3 in the top search bar of the AWS console.
3. Click on CloudShell on the top bar of the AWS console. AWS CloudShell is a browser-based shell that can quickly run scripts with the AWS Command Line Interface (CLI) and experiment with service API’s.
Creating AWS S3 bucket

This will create a command-line environment with an AWS CLI preinstalled.
4. Enter the following command to create a bucket : aws s3 mb s3://<name of bucket\> and hit enter. With the bucket name being unique globally across all AWS regions. Note: Replace the name of the bucket with a descriptive and unique name.

Alternatively, you can create a bucket using the AWS console bucket creation wizard.
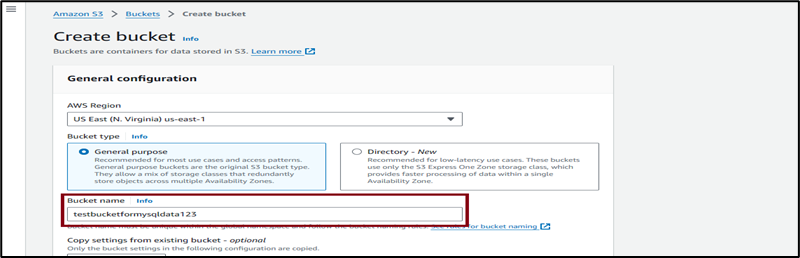
- Click on Create bucket, keep all defaults, enter a globally unique name for the bucket and click Create bucket.
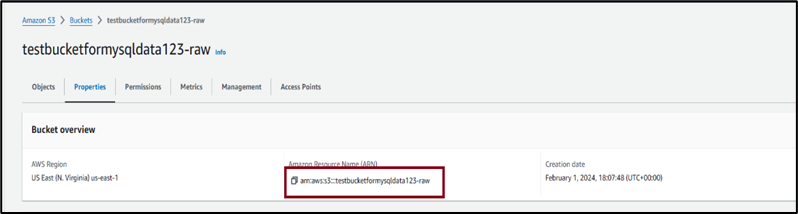
2. After a successful creation of the bucket, click on the name of the bucket and go to the Properties tab. Copy the ARN of the created bucket and save it somewhere, which will be needed in a later step.
This ends the creation of the bucket, which will be used as the destination of all ingested data in this tutorial. Next, we want to set permissions on the created bucket to allow AWS DMS access to the bucket to perform operations on the bucket using AWS Identity and Access Management (IAM). AWS IAM is a web service by AWS that helps you securely control access to AWS resources. It enables you to manage users, groups, and permissions within your AWS environment.
Creating AWS IAM Policy
1. Search for and select IAM in the top search bar of the AWS console.
2. Click on Policies and then click on Create policy. A policy is an object in AWS that defines permissions.
3. By default, the Visual editor tab is selected, so click on JSON to change to the JSON tab. In the actions section, grant all actions on S3 and in the resource section, provide the ARN of the AWS S3 bucket created in the previous steps. Note that in a production environment, the scope of the permission must be limited.
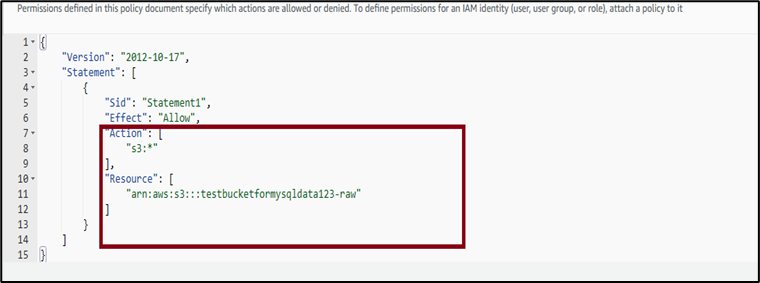
4. Click on Next, provide a descriptive policy name for the policy and click Create policy.
5. In the left-hand menu, click on Roles and then Create role.
6. For the Trusted entity type, choose AWS service, and for Use case select DMS then Next.
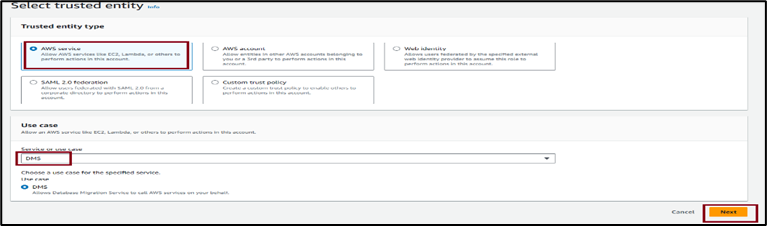
7. Select the policy created in the earlier step and click Next.
8. Provide a descriptive policy name and click Create role.
At this point, we have created an AWS S3 bucket and an IAM role that allows AWS DMS to perform operations on the bucket.
Data ingestion using AWS Data Migration Service
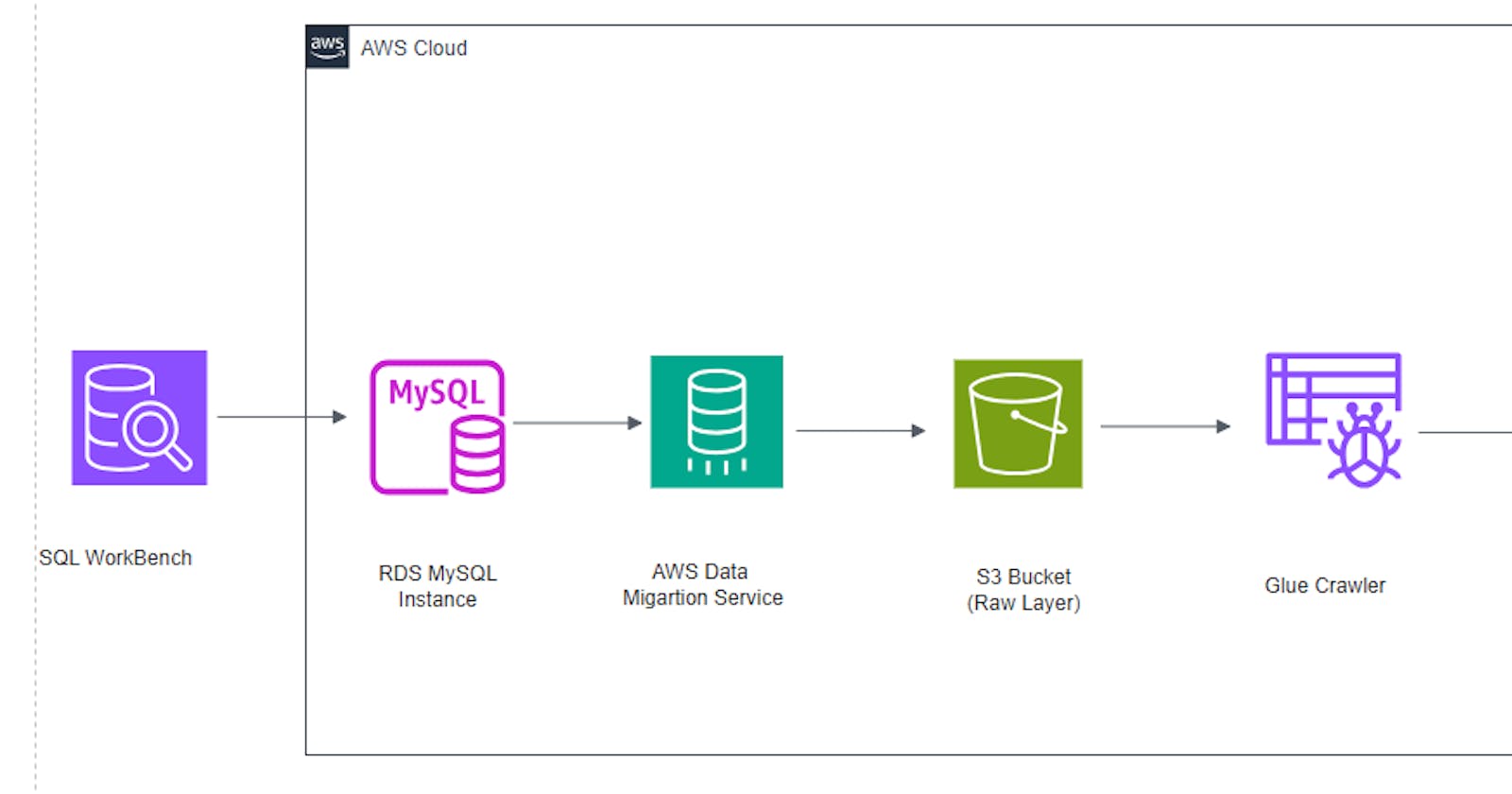
So far, we have created an AWS S3 bucket to host our ingested data. At this point, we will create an AWS Relational Database Service (RDS) MySQL instance, database, and table and populate it with sample data, which will be migrated to AWS S3 as the storage layer using the AWS DMS. We will then crawl the S3 bucket using the Glue Crawler and use the Glue Data Catalog as the metadata repository. We will then query the data using AWS Athena. Below is the architecture of the project.
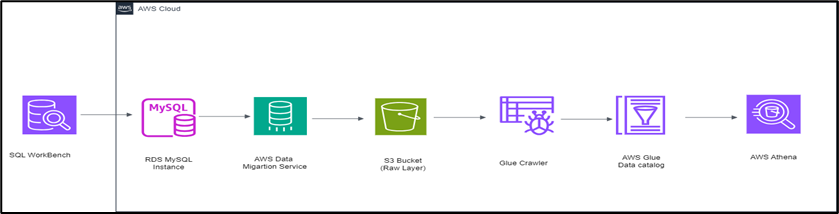
Summary of AWS services used.
1. AWS Relational Database Service is a collection of managed services that makes it simple to set up, operate, and scale databases in the cloud.
2. AWS Database Migration Service is a managed migration and replication service that helps move your database and analytics workloads to AWS quickly, securely, and with minimal downtime and zero data loss.
3. AWS S3 is an object storage service that offers industry-leading scalability, data availability, security, and performance.
4. AWS Glue (Glue Crawler, Glue Data Catalog) is a serverless data integration service that makes it easier to discover, prepare, move, and integrate data from multiple sources for analytics, machine learning (ML), and application development.
5. AWS Athena is an interactive query service that makes it easy to analyze data on Amazon using standard SQL.
Creating AWS RDS MySQL DATABASE
- Search for and select AWS RDS in the top search bar of the AWS console.
2. Click on Databases and select Create database.
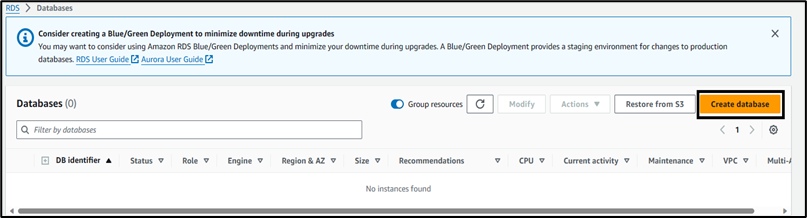
3. Select Easy create for the database creation method. Choosing easy create enables best-practice configuration options that can be changed later.
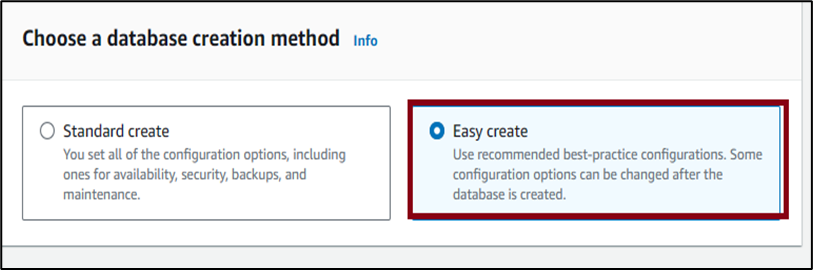
4. Choose MySQL under Configuration.
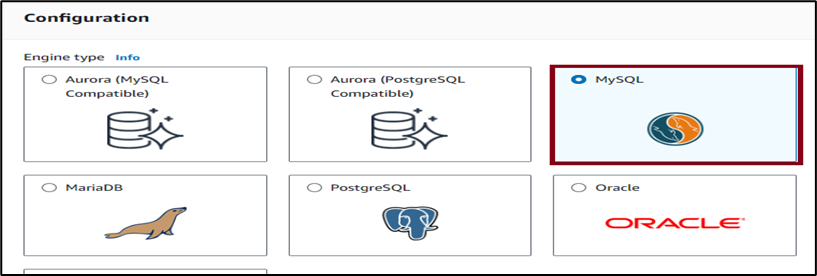
5. Choose Dev/Test under DB instance size. Note: You can also select Free tier for this tutorial.
6. Accept all defaults and enter a Master password and click Create database.
Connecting to AWS RDS MySQL instance using HeidiSQL Client
Let’s populate the database with sample data. Let’s connect to the AWS RDS MySQL instance using an SQL client. In this tutorial, we are using the free HeidiSQL client. You can use any SQL client of your choice.
- If you are using the HeidiSQL client, enter the following details, as shown in the screenshot below: Select Network type as MySQL on RDS. For Hostname/IP copy and paste the Public IPv4 DNS. For User enter the username of the RDS database and Password. Enter 3306 as the Port which is the default for MySQL databases. Note: Make sure you have configured your subnets to allow inbound traffic on port 3306. Click on Open to establish a connection.
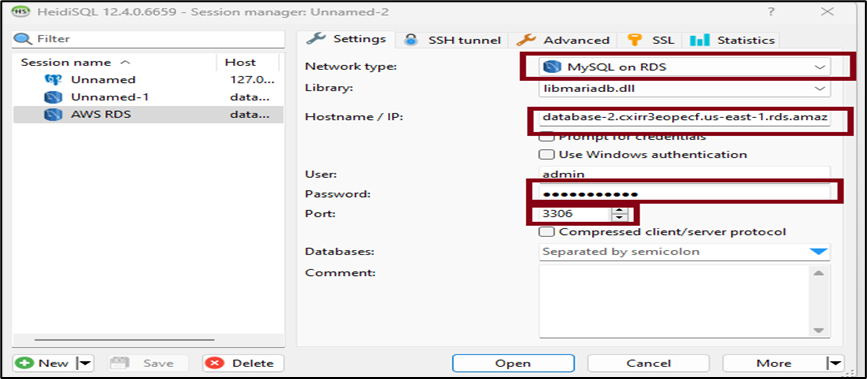
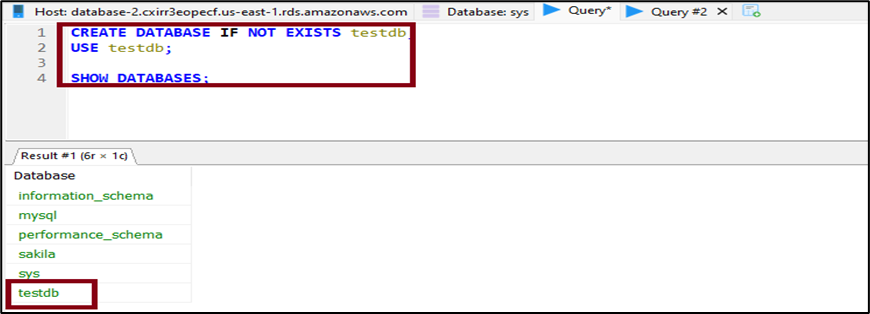
2. After a successful connection, enter the highlighted SQL, as shown in the screenshot below. This creates a database called testdb, sets it as the default database and shows all the created databases with the new database highlighted.
3. Enter the following SQL statement below to create a table in the database.
CREATE TABLE IF NOT EXISTS actor (
actor_id smallint unsigned NOT NULL AUTO_INCREMENT,
first_name varchar (45) NOT NULL,
last_name varchar (45) NOT NULL,
last_update timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP)
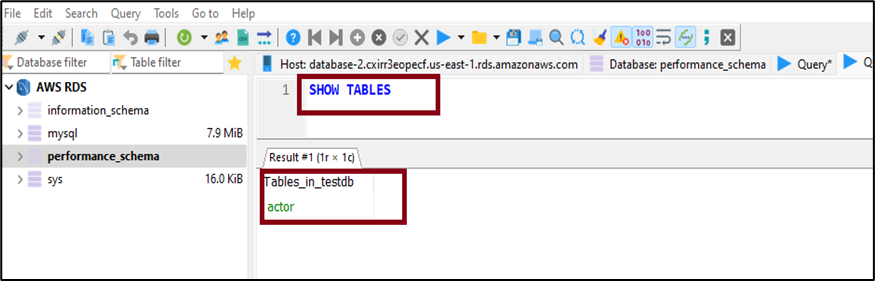
You can also use the ‘SHOW TABLES’ statement to confirm the creation of the table, as shown below.
4. Let’s use the ‘INSERT INTO’ statement to load sample data into the database.

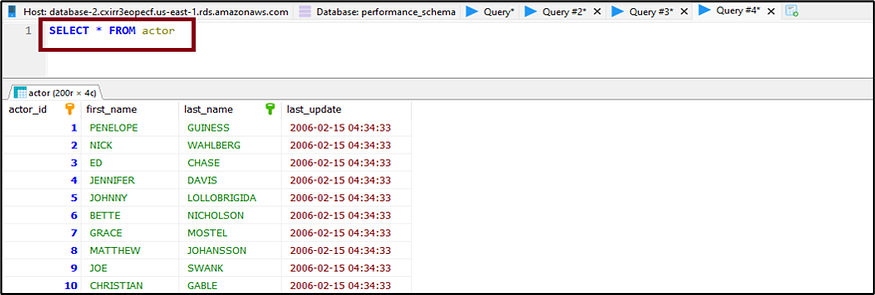
5. Let’s use the ‘SELECT * FROM actor’ to query and verify the inserts.
MIGRATE DATA TO S3 USING AWS DATA MIGRATION SERVICE
- Search for and select AWS Data Migration Service in the top search bar of the AWS console and click on Replication instances. AWS DMS uses a replication instance to connect to your source data store, read the source data, and format the data for consumption by the target data store.
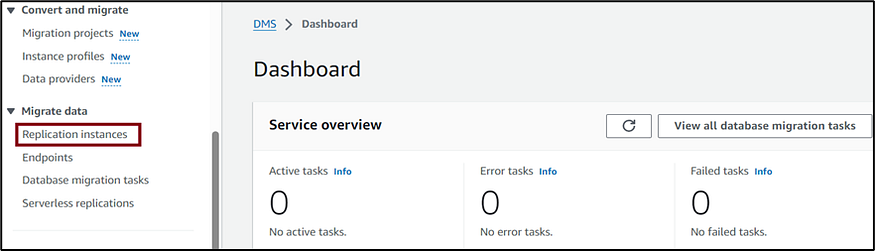
2. Click on Create replication instance to create a replication instance.
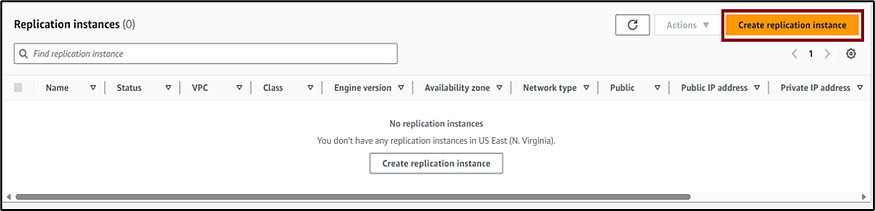
3. Provide a descriptive name and an optional descriptive Amazon Resource Name (ARN) and select an instance class as shown below. Leave all options at their default values, click on Create replication instance and wait for a successful creation of the instance.

4. Next, create an Endpoint. An endpoint provides connection, data store type, and location information about your data store. AWS DMS uses this information to connect to the data store and migrate data from the source endpoint to the target endpoint. We will create two endpoints.
Source endpoint: This allows AWS DMS to read data from a database (on-premises or in the cloud) or other data sources, such as AWS S3.
Target endpoint: This allows AWS DMS to write data to a database, or other stores such as AWS S3 or Amazon DynamoDB.
Choose Source endpoint and select Select RDS DB instance since our source is an Amazon RDS database and select the created AWS RDS database from the RDS drop-down menu. Provide a unique identifier for the endpoint identifier and select MySQL as the source engine. Under Access to endpoint database select provide access information manually and enter the username and password of the AWS RDS MySQL instance. Keep all defaults and click on Create endpoint.
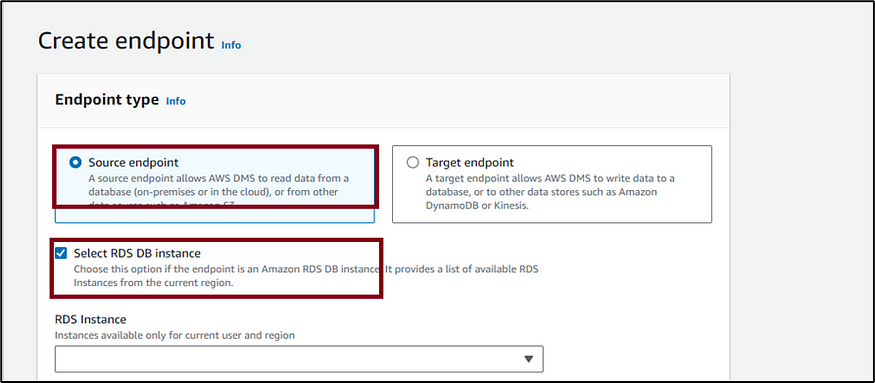
5. Click on Create endpoint again to create a target endpoint. Choose Target endpoint. Provide a label for the endpoint and select Amazon S3 as the target engine. Under Amazon Resource Name (ARN) for the service access role, provide the ARN of the role created earlier (DMSconnectRole). For the Bucket name, enter the name of the bucket created earlier and enter a descriptive name to be used as a folder to store the data under Bucket folder. Click on Create endpoint.
6. Let’s confirm both endpoints.

7. Click on Database migration tasks, then click Create task to create a database migration task. This is where all the work happens. You specify what tables (or views) and schemas to use for your migration and any special processing, such as logging requirements, control table data, and error handling. Under Task identifier, enter a unique identifier for the task (myql-to-s3-task). Under Replication instance, select the created replication instance (mysql-to-s3-replication-vpc-0b6a338c0396b19) in the dropdown. For Source database endpoint, select the created source endpoint (database-2). For Target database endpoint, select the created target endpoint (testbucketformysqldata123-raw-data) from the drop-down list. For Migration type, select Migrate existing data.
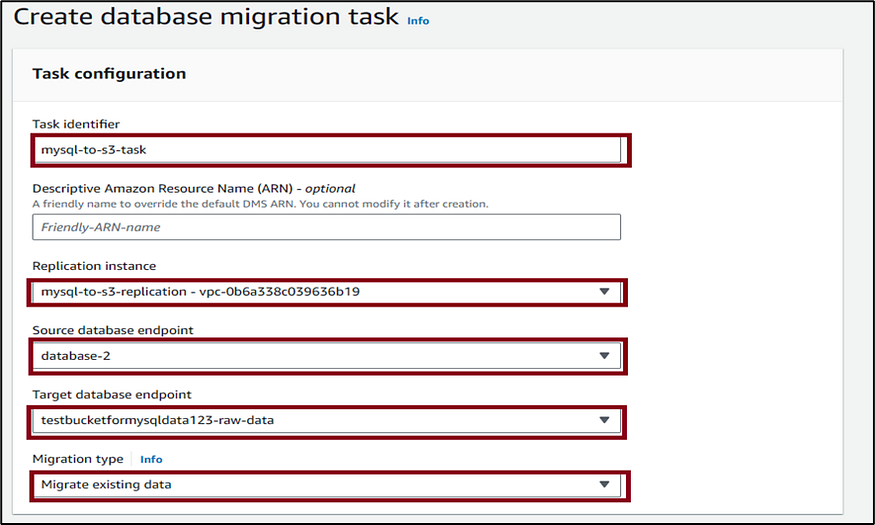
8. Under Table mappings, click on Add new selection rule. Under Schema, select Enter a schema. Under Source name enter the name of the created AWS RDS MySQL database in between the percentage sign. Keep all defaults and click on Create task. This starts the migration task automatically.
9. After a successful migration, the Status shows Load complete, and the progress bar reaches 100%.

10. Let’s confirm the loaded data in the target Amazon S3 bucket.
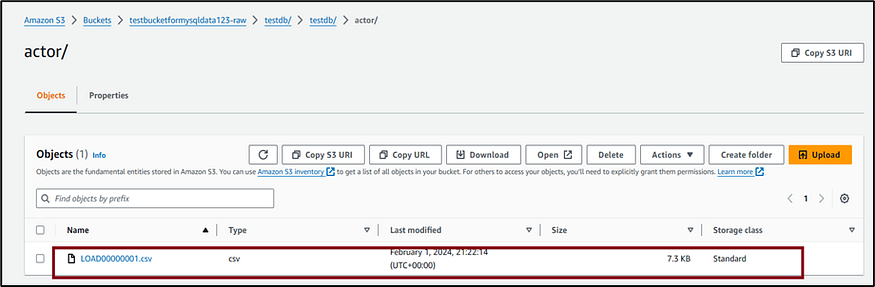
This is the end of the Data ingestion using AWS Services Part 1. Look out for Part 2 of my data ingestion series.